Fresh news
23 Jul 2025
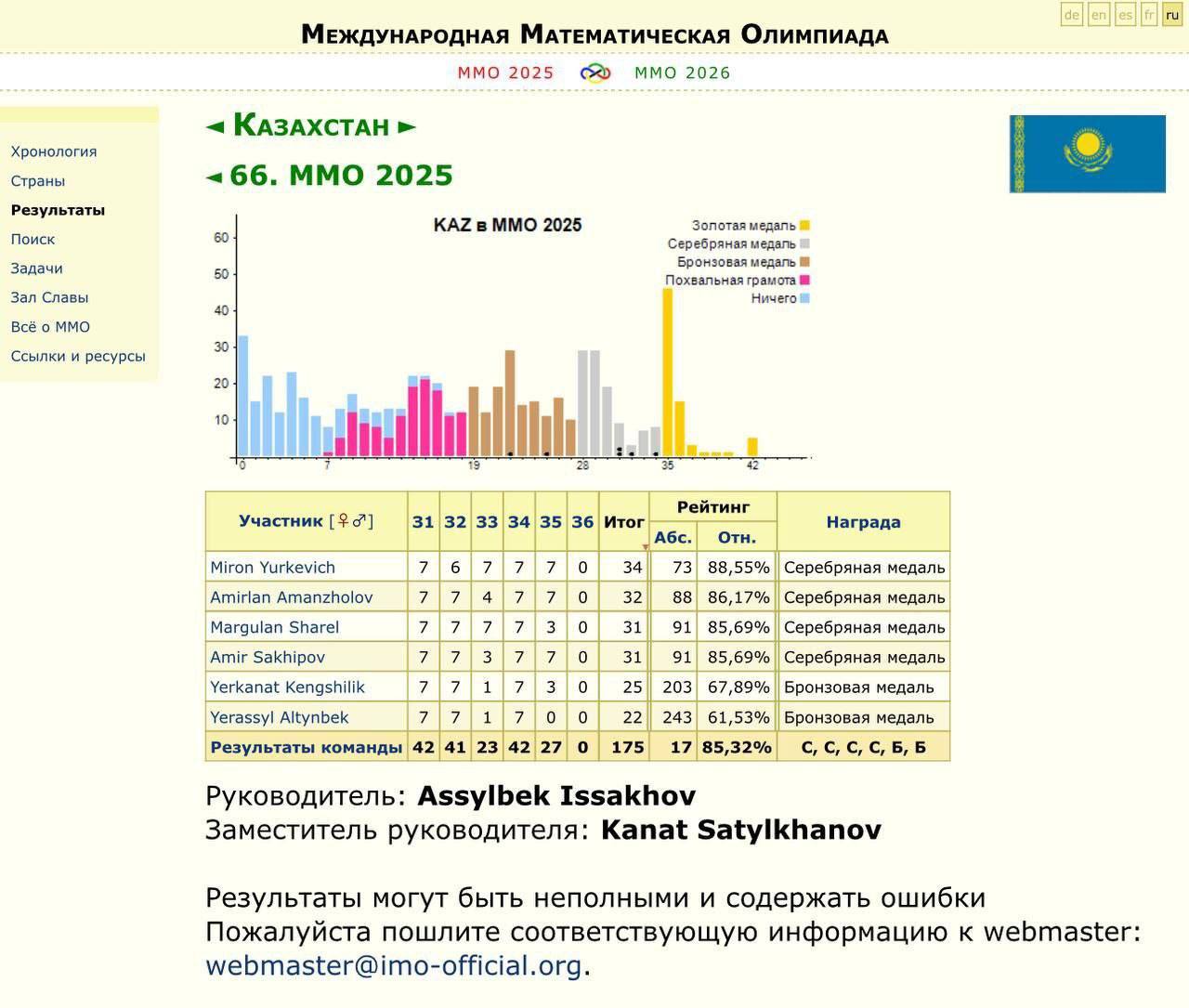
🇰🇿 Казахстан — 6 медалей на IMO 2025
Сборная Казахстана заняла 17-е место среди 110 стран на 66-й Международной математической олимпиаде (IMO 2025), прошедшей в июле в Австралии.
Наши медалисты:
🥈 Miron Yurkevich — 73‑е место
🥈 Amirlan Amanzholov — 82‑е место
🥈 Margulan Sharel — 91‑е место
🥈 Amir Sakhipov — 91‑е место
🥉 Yerkanat Kengshilik — 203‑е место
🥉 Yerassyl Altynbek — 243‑е место
Команда набрала 175 баллов из 252 возможных и вошла в топ‑20 сильнейших в мире. Несмотря на отсутствие золота, этот результат — один из лучших за последние годы, что подтверждает высокий уровень подготовки казахстанских школьников.
Поздравляем участников и наставников с этим достижением!



